
🔗 Mini book review: “The West Divided”, Jürgen Habermas
Written in the early 2000s, “The West Divided” is a collection of interviews, newspaper articles and an essay by Habermas about post-9/11 international politics and the different approaches taken by the US through the Bush administration and the EU, through a philosophical lens.
The structure of the book helps the reader, by starting with transcripts from interviews and articles, which use a more direct language and establish some concepts explained by Habermas to the interviewers, and then proceeding with a more formal academic work in the form of the essay of the last part, which is a more difficult read. Habermas discusses the idealist and realist schools of international relations, aligning the idealist school with Kant’s project and the evolution of the EU, and opposing it to the realist school proposed by authors such as Carl Schmitt, a leading scholar from Nazi Germany. Habermas proposes a future of the Kantian project which lies in the ultimate development of cosmopolitan (i.e. worldwide) juridical institutions, such that cosmopolitan law gives rights directly to (all) people, rather than as a layer of inter-national law between states.
It was especially timely to read this book in the wake of the Russian invasion of Ukraine in February 2022, and to have this theoretical background at hand when watching John Mearsheimer’s talk from 2015 on “Why Ukraine is the West’s Fault”. Mearsheimer, an American professor in the University of Chicago and himself a noted realist, gives an excellent talk and makes a very important point that in international conflict one needs to understand how the other side thinks — instead of “idealist” vs. “realist” (which are clearly loaded terms) he used himself the terms “19th century people” to refer to himself, Putin, and the Chinese leadership, as opposed to “21st century people” to refer to the leaders in the EU and in Washington.
It is interesting to see Mearsheimer put the European and American governments in the same bucket, when Habermas’s book very much deals with the opposition of their views, down to the book’s very title. Habermas wrote “The West Divided” during the Bush administration, and the Mearsheimer talk was given during the Obama years, but he stated he saw no difference between Democrats and Republicans in this regard. Indeed, in what concerns international law, what we’ve seen from Obama wasn’t that different from what we saw before or afterwards — perhaps different in rhetoric, but not so much in actions, as he broke his promise of shutting down Guantanamo and continued the policy of foreign interventions.
As much as Mearsheimer’s analysis is useful to understand Putin, Habermas’s debate that there are different ways to see a future beyond endless Schmittian regional conflicts is still a valid one. And we get a feeling that all is not lost whenever we see that there are still leaders looking to build a future of cosmopolitan cooperation more in line with Kant’s ideals. Martin Kimani, the Kenyan envoy to the UN said this regarding the Russian invasion of Ukraine:
This situation echoes our history. Kenya and almost every African country was birthed by the ending of empire. Our borders were not of our own drawing. They were drawn in the distant colonial metropoles of London, Paris, and Lisbon, with no regard for the ancient nations that they cleaved apart.
Today, across the border of every single African country, live our countrymen with whom we share deep historical, cultural, and linguistic bonds. At independence, had we chosen to pursue states on the basis of ethnic, racial, or religious homogeneity, we would still be waging bloody wars these many decades later.
Instead, we agreed that we would settle for the borders that we inherited, but we would still pursue continental political, economic, and legal integration. Rather than form nations that looked ever backwards into history with a dangerous nostalgia, we chose to look forward to a greatness none of our many nations and peoples had ever known. We chose to follow the rules of the Organisation of African Unity and the United Nations charter, not because our borders satisfied us, but because we wanted something greater, forged in peace.
We believe that all states formed from empires that have collapsed or retreated have many peoples in them yearning for integration with peoples in neighboring states. This is normal and understandable. After all, who does not want to be joined to their brethren and to make common purpose with them? However, Kenya rejects such a yearning from being pursued by force. We must complete our recovery from the embers of dead empires in a way that does not plunge us back into new forms of domination and oppression.
Words to build a new future by.
🔗 The algorithm did it!
Earlier today, statistician Kareem Carr posted this interesting tweet, about what people out there mean when they say “algorithm”, which I found to be a good summary:
When people say “algorithms”, they mean at least four different things:
1. the assumptions and description of the model
2. the process of fitting the model to the data
3. the software that implements fitting the model to the data
4. The output of running that software
Unsurprisingly, this elicited a lot of responses from computer scientists, raising the point that this is not what the word algorithm is supposed to mean (you know, a well-defined sequence of steps transforming inputs into outputs, the usual CS definition), including a response from Grady Booch, a key figure in the history of software engineering.
I could see where both of them were coming from. I responed that Carr’s original tweet not was about what programmers mean when we say “algorithms” but what the laypeople mean when they say it or read it in the media. And understanding this distinction is especially important because variations of “the algorithm did it!” is the new favorite excuse of policymakers in companies and governments alike.
Booch responded to me, clarifying that his point is that “even most laypeople don’t think any of those things”, which I agree with. People have a fuzzy definition of what an algorithm is, at best, and I think Carr’s list encompasses rather well the various things that are responsible for the effects that people credit on a vague notion of “algorithm” when people use that term.
Booch also added that “it’s appropriate to establish and socialize the correct meaning of words”, which simultaneously extends the discussion to a wider scope and also focuses it to the heart of the matter about the use of “algorithm” in our current society.
You see, it’s not about holding on to the original meaning of a word. I’m sure a few responses to Carr were of the pedantic variety, “that’s not what the dictionary says!” kind of thing. But that’s short-sighted, taking a prescriptivist rather than descriptivist view of language. Most of us who care about language are past that debate now, and those of us who adhere to the sociolinguistic view of language even celebrate the fact language shifts, adapts and evolves to suit the use of its speakers.
Shriram Krishnamurthi, CS professor at Brown, joined in on the conversation, observing that this shift in the language as a fait accompli:
I’ve been told by a public figure in France (who is herself a world-class computer scientist) — who is sometimes called upon by shows, government, etc. — that those people DO very much use the word this way. As an algorithms researcher it irks her, but that’s how it is.
Basically, we’ve lost control of the world “algorithm”. It has its narrow meaning but it also has a very broad meaning for which we might instead use “software”, “system”, “model”, etc.
Still, I agreed with Booch that this is still a fight worth fighting. But not to preserve our cherished technical meaning of the term, to the dismay of the pedants among our ranks, but because of the observation of the very circumstances that led to this linguistic shift.
The use of “algorithm” as a vague term to mean “computers deciding things” has a clear political intent: shifting blame. Social networks boosting hate speech? Sorry, the recommendation algorithm did it. Racist bias in criminal systems? Sorry, it was the algorithm.
When you think about it, from a linguistic point of view, it is as nonsensical as saying that “my hammer assembled the shelf in my living room”. No, I did, using the hammer. Yet, people are trained to use such constructs all the time: “the pedestrian was hit by a car”. Note the use of passive voice to shift the focus away from the active subject: “a car hit a pedestrian” has a different ring to it, and, while still giving agency to a lifeless object, is one step closer to making you realize that it was the driver who hit the pedestrian, using the car, just like it was I who built the shelf, using the hammer.
This of course leads to the “guns don’t kill people, people kill people” response. Yes, it does, and the exact same questions regarding guns also apply regarding “algorithms” — and here I use the term in the “broader” sense as put forward by Carr and observed by Krishnamurthi. Those “algorithms” — those models, systems, collections of data, programs manipulating this data — wield immense power in our society, even, like guns, resulting in violence, and like guns, deserving scrutiny. And when those in possession of those “algorithms” go under scrutiny, they really don’t like it. One only needs to look at the fallout resulting from the work by Bender, Gebru, McMillan-Major and Mitchell, about the dangers of extremely large language models in machine learning. Some people don’t like hearing the suggestion that maybe overpowered weapons are not a good idea.
By hiding all those issues behind the word “algorithm”, policymakers will always find a friendly computer scientist available to say that yes, an algorithm is a neutral thing, after all, it’s just a sequence of instructions, and they will no doubt profit from this confusion of meanings. And I must clarify that by policymakers I mean those both in public and private sphere, since policies put forward by the private tech giants on their platforms, where we spend so much of our lives, are as effecting on our society as public policies nowadays.
So what do we do? I don’t think it is productive to start well-actually-ing anyone who uses “algorithm” in the broader sense, with a pedantic “Let me interject for a moment — what you mean by algorithm is in reality a…”. But it is productive to spot when this broad term is being used to hide something else. “The algorithm is biased” — What do you mean, the outputs are biased? Why, is the input data biased? The people manipulating that data created a biased process? Who are they? Why did they choose this process and not another? These are better interjections to make.
These broad systems described by Carr above ultimately run on code. There are algorithms inside them, processing those inputs, generating those outputs. The use of “algorithm” to describe the whole may have started as a harmless metonymy (like when saying “White House” to refer to the entire US government), but it has since been proven very useful as a deflection tactic. By using a word that people don’t understand, the message is “computers doing something you don’t understand and shouldn’t worry about”, using “algorithm” handwavily to drift people’s minds away from the policy issues around computation, the same way “cloud” is used with data: “your data? don’t worry, it’s in the cloud”.
Carr is right, these are all things encompassing things that people refer to as “algorithms” nowadays. Krishnamurthi is right, this broad meaning is a reality in modern language. And Booch is right when he says that “words matter; facts matter”.
Holding words to their stricter meanings merely due to our love for the language-as-we-were-taught is a fool’s errand; language changes whether we want it or not. But our duty as technologists is to identify the interplay of the language, our field, and society, how and why they are being used (both the language and our field!). We need to clarify to people what the pieces at play really are when they say “algorithm”. We need to constantly emphasize to the public that there’s no magic behind the curtain, and, most importantly, that all policies are due to human choices.
🔗 Again on 0-based vs. 1-based indexing
André Garzia made a nice blog post called “Lua, a misunderstood language” recently, and unfortunately (but perhaps unsurprisingly) a bulk of HN comments on it was about the age-old 0-based vs. 1-based indexing debate. You see, Lua uses 1-based indexing, and lots of programmers claimed this is unnatural because “every other language out there” uses 0-based indexing.
I’ll brush aside quickly the fact that this is not true — 1-based indexing has a long history, all the way from Fortran, COBOL, Pascal, Ada, Smalltalk, etc. — and I’ll grant that the vast majority of popular languages in the industry nowadays are 0-based. So, let’s avoid the popularity contest and address the claim that 0-based indexing is “inherently better”, or worse, “more natural”.
It really shows how conditioned an entire community can be when they find the statement “given a list x, the first item in x is x[1], the second item in x is x[2]” to be unnatural. :) And in fact this is a somewhat scary thought about groupthink outside of programming even!
I guess I shouldn’t be surprised by groupthink coming from HN, but it was also alarming how a bunch of the HN comments gave nearly identical responses, all linking to the same writing by Dijkstra defending 0-based indexing as inherently better, as an implicit Appeal to Authority. (Well, I did read Dijkstra’s note years ago and wasn’t particularly convinced by it — not the first time I disagree with Dijkstra, by the way — but if we’re giving it extra weight for coming from one of our field’s legends, then the list of 1-based languages above gives me a much longer list of legends who disagree — not to mention standard mathematical notation which is rooted on a much greater history.)
I think that a better thought, instead of trying to defend 1-based indexing, is to try to answer the question “why is 0-based indexing even a thing in programming languages?” — of course, nowadays the number one reason is tradition and familiarity given other popular languages, and I think even proponents of 0-based indexing would agree, in spite of the fact that most of them wouldn’t even notice that they don’t call it a number zero reason. But if the main reason for something is tradition, then it’s important to know how did the tradition start. It wasn’t with Dijkstra.
C is pointed as the popularizer of this style. C’s well-known history points to BCPL by Martin Richards as its predecessor, a language designed to be simple to write a compiler for. One of the simplifications carried over to C: array indexing and pointer offsets were mashed together.
It’s telling how, whenever people go into non-Appeal-to-Authority arguments to defend 0-based indexes (including Dijkstra himself), people start talking about offsets. That’s because offsets are naturally 0-based, being a relative measurement: here + 0 = here; here + 1 meter = 1 meter away from here, and so on. Just like numeric indexes are identifiers for elements of an ordered object, and thus use the 1-based ordinal numbers: the first card in the deck, the second in the deck, etc.
BCPL, back in 1967, made a shortcut and made it so that p[i] (an index) was equal to p + i an offset. C inherited that. And nowadays, all arguments that say that indexes should be 0-based are actually arguments that offsets are 0-based, indexes are offsets, therefore indexes should be 0-based. That’s a circular argument. Even Dijkstra’s argument also starts with the calculation of differences, i.e., doing “pointer arithmetic” (offsets), not indexing.
Nowadays, people just repeat these arguments over and over, because “C won”, and now that tiny compiler-writing shortcut from the 1960s appears in Java, C#, Python, Perl, PHP, JavaScript and so on, even though none of these languages even have pointer arithmetic.
What’s funny to think about is that if instead C had not done that and used 1-based indexing, people today would certainly be claiming how C is superior for providing both 1-based indexing with p[i] and 0-based pointer offsets with p + i. I can easily visualize how people would argue that was the best design because there are always scenarios where one leads to more natural expressions than the other (similar to having both x++ and ++x), and how newcomers getting them mixed up were clearly not suited for the subtleties of low-level programming in C, and should be instead using simpler languages with garbage collection and without 0-based pointer arithmetic.
🔗 User power, not power users: htop and its design philosophy
What the principles that underlie the software you make?
This short story is not really about htop, or about the feature request that I’ll use as an illustration, but about what are the core principles that drive the development of a bit of software, down to every last detail. And by “core principles” I really mean it.
When we develop software, we have to make a million decisions. We’re often driven by some unspoken general principles, ranging from our personal aesthetics on the external visuals, to our sense of what makes a good UX in the product behavior, to things such as “where does bloat cross the line” in the engineering internals. In FOSS, we’re often wearing all these hats at the same time.
We don’t always have it clear in our mind what drives those principles, we often “just know”. There’s no better opportunity to assess those principles than when user feedback asks for a change in the behavior. And there’s no better way to explain to yourself why the change “feels wrong” than to put those principles in writing.
Today was one such opportunity.
I was peeking at the htop issue tracker as an end-user, which is a refreshing experience, having recently retired from this FOSS project I started. I spotted a feature request, asking for a change to make it hide threads by default.
The rationale was sensible:
People casually using htop usually have no idea what userland threads are for.
People who actually need to see them can easily enable them via SHIFT+H.With them currently enabled by default, it is very inconvenient to go through the list and see what is running, taking up RAM, CPU usage and whatnot, therefore I think it’d be more user-friendly to not show them by default.
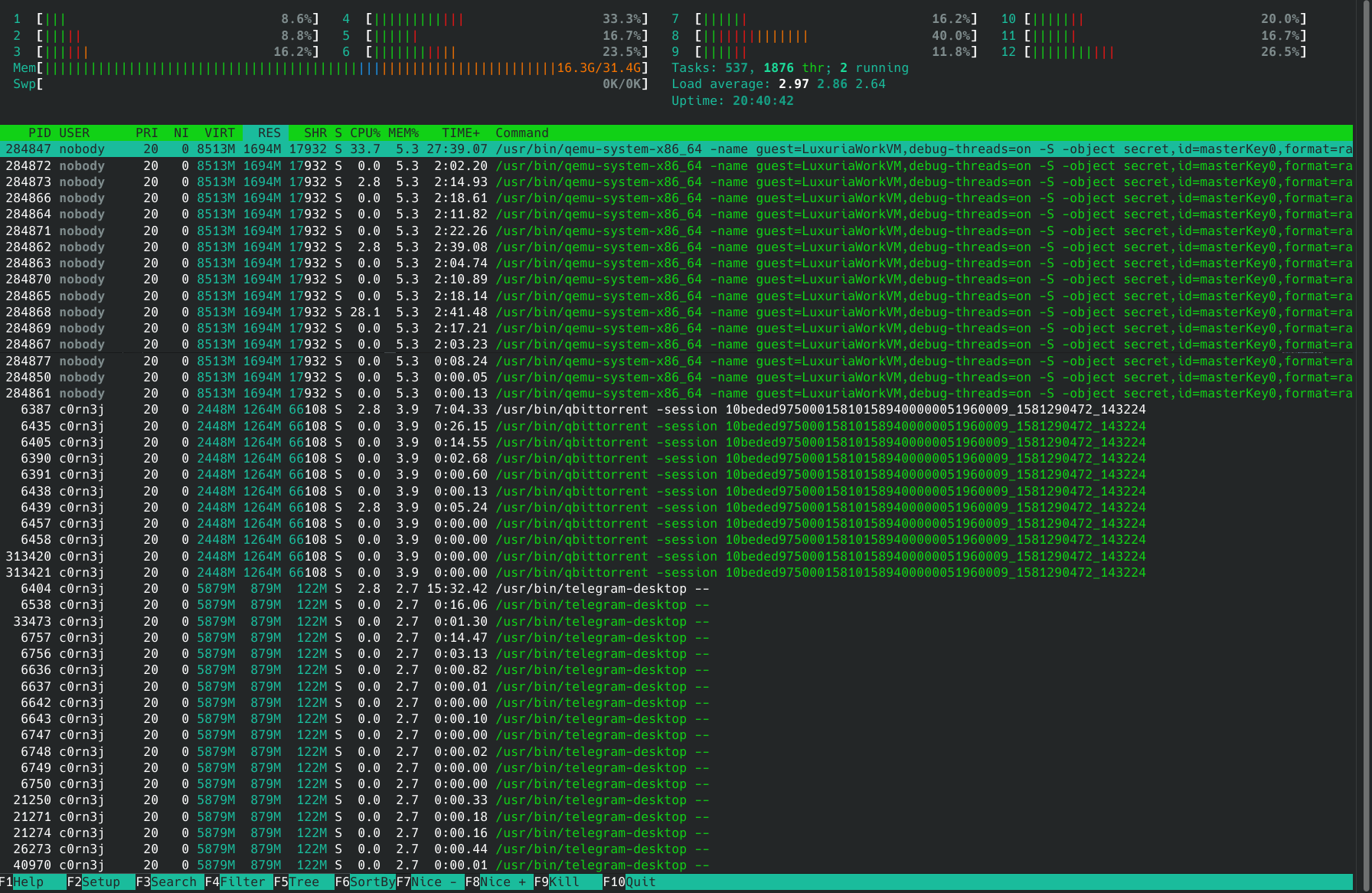
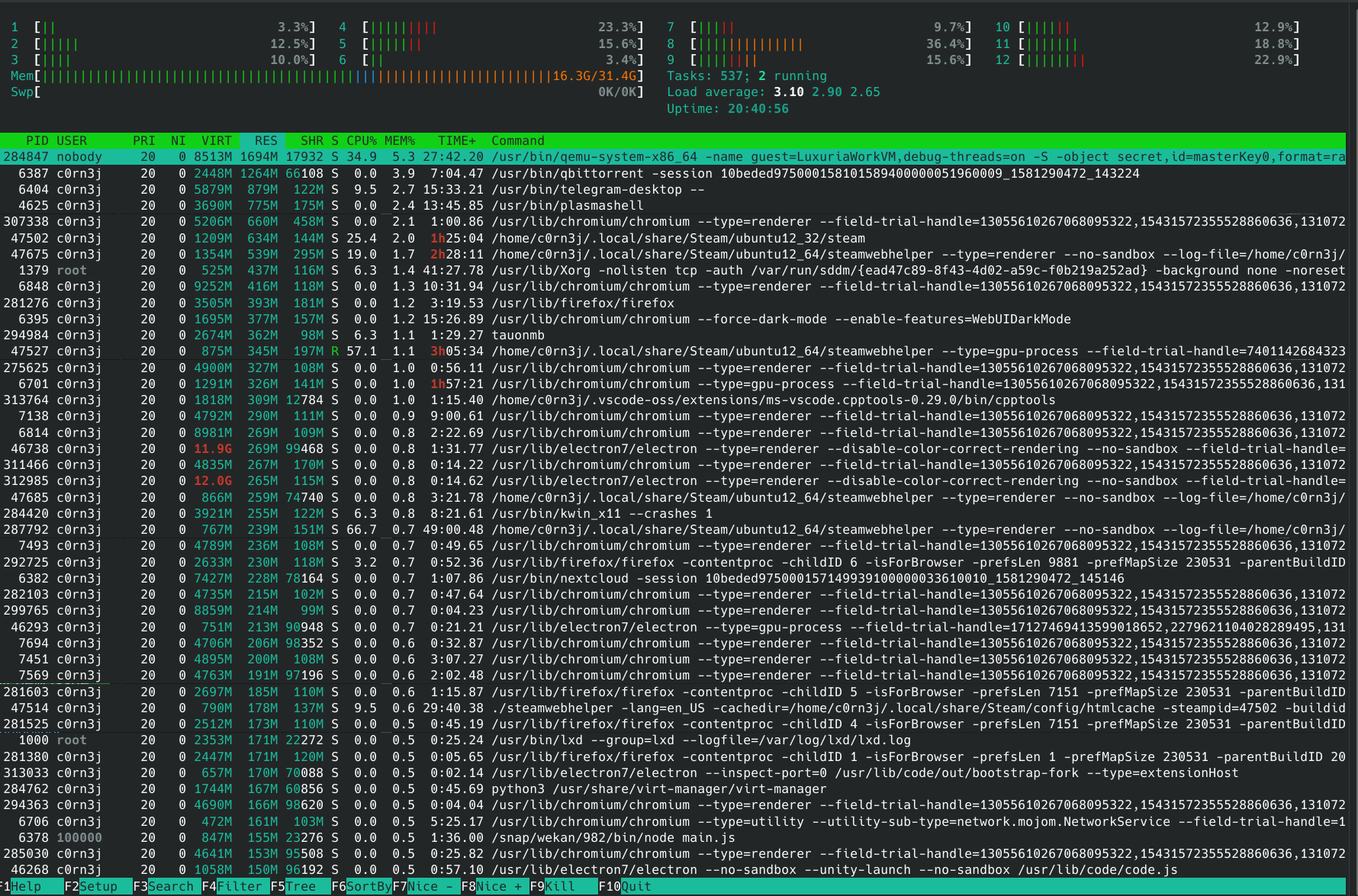
He proceeded to show two screenshots: one with the default behavior, full of threads (in green) mixed with the processes, and another with threads disabled.
When one of the current developers said that it’s easier for the user to figure out how to hide things than for them to discover that something hidden can be shown, the counter-argument was also sensible:
Htop can also show Disk IO, which can be arguably very useful, but is hidden by default.
At that point, I decided to put my “original author” hat on to explain what was the intent behind the existing behavior. Here’s what I wrote:
Hi @C0rn3j, I thought I’d drop by and give a bit of historical background as to what was my motivation for showing threads by default.
People casually using htop usually have no idea what userland threads are for.
Yes! I fully sympathize with this sentiment. And the choice for enabling threads and painting them green was deliberate.
You have no idea how many times I was asked “hey, why are some processes green?” over these 15+ years — and no, it wasn’t annoying: each of these times it was an opportunity to teach someone about threads!

{kind=link}
{kind=link}
htop was designed to provide a view to what’s going on in the system. If a process is spawning threads like crazy, or if all your cores are overwhelmed because multiple threads of a process are doing work, I think it’s fair to show it to the user, even if they don’t know a thing about threads — or I would say, especially if they don’t know a thing about threads, otherwise these things would be happening and they wouldn’t even know where to look.
Htop can also show Disk IO, which can be arguably very useful, but is hidden by default.
One of my last projects when I was still active in htop development was to add tabs to the interface, so that the user would have a more discoverable path for navigating through these additional columns:

This code is in the next branch of the old repo https://github.com/hishamhm/htop/ — I think the code for tabs is actually finished (though not super tested); it’s pretty nice, you can click on them or cycle with the Tab key, but the Perf Counters support which I was working on, never really got stable to a point of my liking, and that’s when I got busy with other things and drifted away from development — turns out I enjoy writing interface code a lot more than the systems monitoring part!
Anyway, I think that also illustrates the pattern that went into the design: I implemented the entire tabs feature because I wanted to make IO and Perf Counters more discoverable. I wanted to put that information in front of users faces, especially for users who don’t know about these things! I considered the fact that I had implemented the entire functionality of iotop inside htop but people didn’t know about it to be a personal failure, and a practical learning experience: adding systems functionality is useless if the UI design doesn’t get it to users’ hands. (And even I didn’t use the IO features because there was no convenient way of using them.)
I never wanted to implement a tool for “super advanced Linux power users who know what they doing”, otherwise I would have never spent a full line at the bottom showing F-keys, and I would have spent my time implementing Vim bindings (ugh ;) ) instead of mouse support. I’ve always made a point that every setting can be settable via the Setup screen, which you can access via F2-Setup (shown at the bottom line!) and which you can control with the keyboard or mouse, no “edit this config file to use this advanced feature for the initiated only” or even “read the man page” (in fact it only has a man page because Debian developers contributed it!).
I wanted to make a tool that has the power but doesn’t hide it from users, and instead invites users into becoming more powerful. A tool that reaches out its hand and guides them along the way, helping users to educate themselves about what’s happening on the internals of their system, and in this way have more control of it. This is how you hand power to users, not by erecting barriers of initiation or by giving them the bare minimum they need. I reject this dicothomy between “complicated tools for power users” and “stripped-down tools for mere mortals”, the latter being a design paradigm made popular by certain companies and unfortunately copied by so many OSS GUI projects, without realizing what the goals of that paradigm really were, but that’s another rant.
And that’s why threads are enabled by default, and colored in green!
(PS: and to put the point to the proof, I must say that the tabs feature was a much bigger code change than Perf Counters themselves; it included some quite big internal refactors (there’s no “toolkit”, everything is drawn “by hand” by htop) with unfortunately might make it difficult to ressurect that code (or not! who knows?), and of course tabs are user-definable and user-editable!)
The user who proposed the change in the defaults thanked me for the history tidbits and closed the feature request. But in some sense writing this down was probably more enlightening to me than it was for them.
When I started writing htop, I did not set out to create “an instrument for user empowerment” or any such lofty goal. (All I wanted was to have a top that scrolled and was more forgiving with mistypes than circa-2005 top!) But as I proceeded to write the software, every small decision had to come from somewhere, even if done without much deliberate thought, even if at the time it was just “it felt right”. That’s how your principles start to percolate into the project.
Over time, the picture I described in that reply above became clear to me. It helped me build practical guidelines, such as “every setting must be UI-accessible”, it helped me prioritize or even reject feature requests based on how much they aligned to those principles, and it helped me build a sense of purpose for the software I was working on.
If you don’t have it clear to yourself what are the principles that are foundational to the software you’re building, I recommend you to give this exercise a try — try to explain why the things in the software are the way they are. There are always principles, even if they are not conscious to you at the moment.
(PS: It would be awesome if some enterprising soul would dig down the tab support code and ressurrect it for htop 3! I don’t plan to do so myself any time soon, but all the necessary bits and pieces are there!)
🔗 Talking htop at the Changelog podcast
I was interviewed at the Changelog podcast about the surprising story of the maintainership transition in htop:
The Changelog 413: How open source saved htop – Listen on Changelog.com
Follow
🐘 Mastodon ▪ RSS (English), RSS (português), RSS (todos / all)
Last 10 entries
- Aniversário do Hisham 2026
- Aniversário do Hisham 2025
- The aesthetics of color palettes
- Western civilization
- Why I no longer say "conservative" when I mean "cautious"
- Sorting "git branch" with most recent branches last
- Frustrating Software
- What every programmer should know about what every programmer should know
- A degradação da web em tempos de IA não é acidental
- There are two very different things called "package managers"